

7 Foundational Data Modeling Concepts
An introduction to the foundations of good data modeling
Data modeling is a foundational skill of any analytics engineer.
The more you do it, the better you get at it.
To prepare you for the on-the-job experience required to master the art of modeling, you need to build a strong foundational knowledge.
This includes understanding:
facts and dimensions
star schemas
slowly changing dimensions
data vault modeling
normalization vs denormalization
3NF vs dimensional data modeling
top-down vs bottom-down approach
With a strong understanding of the above, you can feel confident looking at raw data, speaking with the business about their needs, and determining a course of action to piece these together into a data model.
Don’t forget to join me live on Substack at 8 am PST tomorrow Friday, September 12th, for The Friday Grind. I’ll answer any questions you have about data modeling, analytics engineering, the job market, and more!

Facts and Dimensions
Dimensional data modeling is a method designed by Ralph Kimball that focuses on identifying key business practices and then building out the foundation of these practices before adding additional tables.
Ralph Kimball’s dimensional model techniques separate data into fact and dimension tables.
I like to think of fact tables as tables produced by different events that occur within a business. Actions in a business are typically represented as fact tables within the data warehouse.
Unlike fact tables which capture business events, dimension tables contain descriptive attributes. They are usually wide, flat tables that are also denormalized. They have a single primary key which exists as a foreign key in a fact table. Foreign keys in fact tables directly relate to the primary keys of dimension tables.
Dimension tables rarely change from day to day within a business while fact tables are always changing.
Star Schemas
Star schemas are named this way because of their shape! A star schema describes a fact table surrounded by various dimension tables. They were introduced by Ralph Kimball in the 90s as part of dimensional data modeling.

Star schemas are shaped this way due to a central fact table having multiple foreign keys, each mapping to the primary key of a dimension table. This way of storing data makes it fast to transform data in different tables for analytics use cases.
Slowly Changing Dimensions
A slowly changing dimension is a data record whose values change slowly over time.
A customer’s account data like email, address, and phone number is an example of a slowly changing dimension. The customer’s address won’t change every day, but it may change every two years.
The type of slowly changing dimension depends on how the changes are tracked in your database.
For example, Type 1 Slowly Changing Dimensions overwrite old values in your data. The new value will replace the old value, without any record of what the old value was. I find this is the method used in most databases.
Type 2 Slowly Changing Dimensions insert new values as new records in your database. They maintain the “old” records AND the new records. They have additional fields on the records that indicate a version number or the timestamps in which the value is effective.
Type 3 slowly changing dimensions maintain one record for the original primary key but utilize an “original” value field and a “current” value field. They track the previous and current values of a field in one record. However, this means they only track the most recent change in value and not the entire history of changes.
Type 4 slowly changing dimensions use two tables to represent one object. They use a table to store current values, and another table to store historical values. The history table contains one timestamp field that you can then use to piece together the chronological history of values.
Data Vault Modeling
Data vaults differ from dimensional data modeling in that they are built to serve enterprise companies, helping them to scale their data. They consist of three main entities- hubs, links, and satellites.
You can think of hubs as the main business objects (like customers or products).
Links represent the relationships between hubs.
Satellites store all the information about the concepts and their relationships (similar to dimensions in dimensional data modeling).
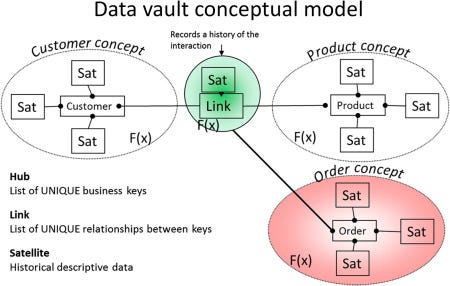
This way of modeling is particularly beneficial for companies utilizing a data lakehouse rather than a data warehouse, as it can handle large volumes of less structured data.
Normalization vs Denormalization
Normalization refers to the process of ensuring there is no redundant data in your relational database. It makes your data easy to query and scale as new data is added to the table.
Your source data in your relational databases should always be normalized. However, your transformed data is another story.
Normalized data will:
have a primary key
not be dependent on row order
have fields with values of all the same data type
These qualities can also be referred to as First Normal Form (1NF), which is the most basic form of normalization.
Denormalization
As you may imagine, denormalization is the opposite of normalization. It is when you introduce redundancy into your normalized data.
Why would someone want to do this? It can be helpful to have a field whose values are redundant be easily accessible in a data model.
Including a customer_id in an orders model would be a good example of this. Many orders will have the same customer name, but this is helpful information to have when you want to find the number of orders placed by each customer.
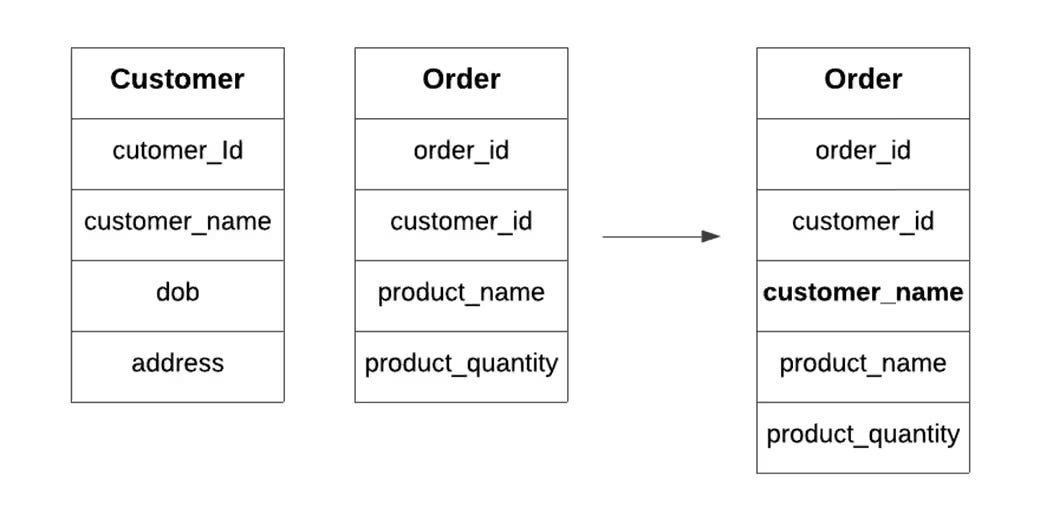
Dimensional data models and transformations within dbt will consist of denormalized data since they are optimized to reduce the number of joins needed downstream.
Models with derived fields are also considered denormalized.
