

dbt Fusion Has People Divided- Here's Why
The big questions: Is Core disappearing? Does Fusion deliver on its promises?
Anything that elicits such strong responses (in both directions) from a community deserves to be talked about further. Based on the title, you probably already know I’m talking about dbt Labs’ new engine called dbt Fusion.
A lot of people were confused by the recent launch of dbt Fusion. Many were scared that dbt would no longer offer an open-source product at all. A lot of people didn’t understand what the big release was about, saying it wasn’t fully fleshed out.
There were also people who were over-the-moon thrilled about the launch, particularly for faster parsing time and automatic error detection using the new VSCode extension.

I sit somewhere in the middle. I’m not sure it will be as impactful for most data teams as it’s been made to seem, but I do think it will add ease to the overall development experience. I see dbt Fusion as something that had to be built to take dbt Labs to the next phase. It is a stepping stone to get where they wanted to go, packaged as a powerful feature for its users.
We’ll get more into it in a second, but first, let’s talk about what dbt Fusion is and the changes that came with it.
What is dbt Fusion?
If you aren’t familiar with dbt Fusion and what it does, here is a little overview.
dbt is composed of two parts- an authoring layer (the project that you see and actively work in) and an engine (how it all works under the hood).
dbt Fusion is a revamp of the engine aka the part of dbt that you can’t see.
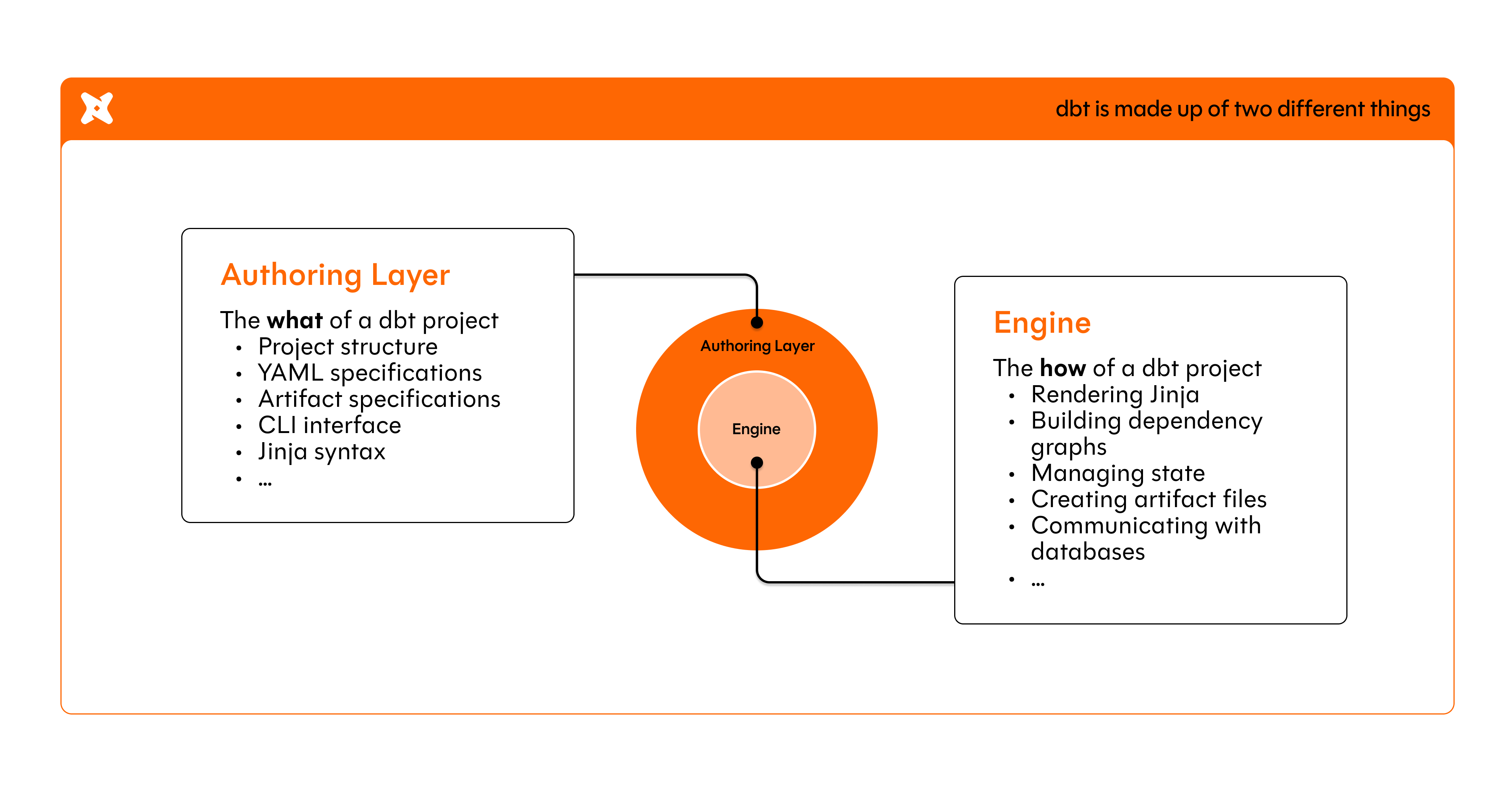
Without getting into the nitty-gritty technical details, there were aspects of dbt’s previous underlying engine that wouldn’t allow them to fully bake in the functionalities they wanted.
dbt Fusion is a true SQL compiler. Because of this, it can point out issues before you run your dbt models. This has allowed them to build their own VSCode extension and follow state-awareness orchestration (only building the things that have changed).
Why should you care about how dbt compiles SQL?
“When you're waiting a few seconds or a few minutes for things to start happening after you invoke dbt, it's because parsing isn't finished yet.”
- Joel Labes
Essentially, the reason dbt was slow for you before this new engine is because of how it parsed and compiled code.
Why should I care?
This increases development speeds 30x and decreases cost.
This is a pretty big impact if you have a large dbt project with a ton of models. This will save you money on resources and help you deliver what you need at faster speeds (you’re only running what’s changed!).
However, if your dbt project is relatively small (which has always been the case for me), this probably won’t matter much to you. Small projects are often fast enough. A few seconds, or even minutes, most likely won’t move the needle for you.
This allows for faster dbt development.
The engine change allowed dbt to develop a VSCode package. This package allows you to detect errors in your model without running your dbt models, propagate changes in field and model names throughout your project, and navigate directly to referenced sources.
If you’re interested in seeing it in action, Bruno Lima gave a great demo of this on LinkedIn the other day.

While I don’t think this feature is life-changing, it does make the lives of dbt developers easier. When every tool is working to make development smart, not including them could cost you a customer’s loyalty. dbt had to optimize the developer experience at some point.
