

The Truth of Self-Service Analytics
4 things your data team needs to start doing now to make this possible in the BI layer
Self-service analytics is a state of mind. It’s a culture. It requires full commitment from every member of a data team to be done right.
Most data teams have an ultimate goal of providing self-serve analytics, but never truly get there. Why is this? They often aren’t willing to go through the pain required to shift the current culture and state of mind.
When I joined the data team at Kit, we were in a vicious cycle of over-committing and rushing to deliver on stakeholders’ every wish. Instead of prioritizing and saying no, we would say yes to everything.
This led to a lot of one-off reporting queries and dashboards that couldn’t be reused. With every new request came a new data product that had to be built from scratch.
This is a natural pattern that many data teams without analytics engineers fall into. Data analysts don’t naturally build scalable data products, so everything becomes quick and dirty without much thought about the future. Tech debt continues to build in an effort to keep up with all the work coming in. Highly impactful projects get pushed to the back burner because there’s simply no extra time to work on them.
There comes a point in time when you have to put an end to this cycle. Because if you don’t, it will only continue until it implodes on itself.
To get to a spot where BI is truly self-service, a few things first need to happen:
You’ve created a culture of ruthless prioritization where everything built is tied to a company KPI or goal.
You focus on solving underlying problems rather than providing exactly what a stakeholder has asked for.
You’ve created foundational data models that can answer many different business questions.
You’ve educated your stakeholders on proper data and AI practices, differences between high and low quality data, and how to use your company data models.
What even is self-service BI?
Self-service is one of those terms that have been overly used in the data space. There was a time when everything had “self-serve” slapped in front of it. However, now with AI becoming baked into BI tools like Count, self-serve is finally becoming realistic.
Self-service means stakeholders have the data they need to explore and dig into their questions, without the help of the data team. It means they can feel confidant about the answers they are getting without needing to ask the data team to confirm if their answers are correct.
In short, self-service BI should be entirely disconnected from the data team apart from the initial work of getting the data available and ready to use within the BI tool.
Does your BI tool matter?
While I’ve always been skeptical that you need certain BI tools to enable self-service BI, I’ve used tools that make it nearly impossible to achieve this. After using Quicksight for nearly 2 years, I’ve realized that the tools available to you really do make a difference.
In today’s world, you absolutely need a BI tool with a high-quality, built-in AI agent to achieve self-service. Having an AI agent available to a stakeholder allows them to mimic 5+ years of experience diving into quality data and metrics that they otherwise wouldn’t have.
This means minimal data training for major impact.
Count’s AI agent, for example, allows stakeholders to follow its exact thought process, seeing what it’s looking at and thinking through to answer their question. This not only gives them the answer faster, but it allows them to learn from the agent and also question it when something in the process seems off.

It’s really important to work with AI agents that aren’t black boxes for this very reason. It puts discernment in the hands of the user still, empowering them throughout the process rather than giving over full control.
Of course, with this, I do want to emphasize the importance of having foundational data models that make this possible. AI agents like the one offered by Count have an easier time understanding data that is well-modeled compared to raw data. With raw data comes a higher likelihood of business logic being inferred and therefore incorrect.
Data modeling for AI agents
You can’t have self-service BI without well-built, scalable, high-quality data models. This is something no amount of AI capabilities will be able to replace.
Data models give your AI agents direction. They act as a map of business processes. Let’s look at two examples using the same data and same business questions. In the first example we are using the raw data with the AI agent and in the second we are using modeled data with the AI agent.
EX: Feeding AI agents raw data
I start by giving Count the raw data tables I want it to use to help me understand subscription plan changes. Because it doesn’t yet know the relationships between the tables, it explores the patterns between them, inferring their relationship.

It then begins to build its own set of core models. While these were actually pretty accurate, it created many different models at different grains rather than one core subscription plan changes model, which is all we really need.

This can be confusing for stakeholders to follow, as the models are at different grains, built for different use cases, and are not clearly documented with the business logic they are modeled after. Even if the agent is able to extract the correct insights, it makes it harder for stakeholders to validate.

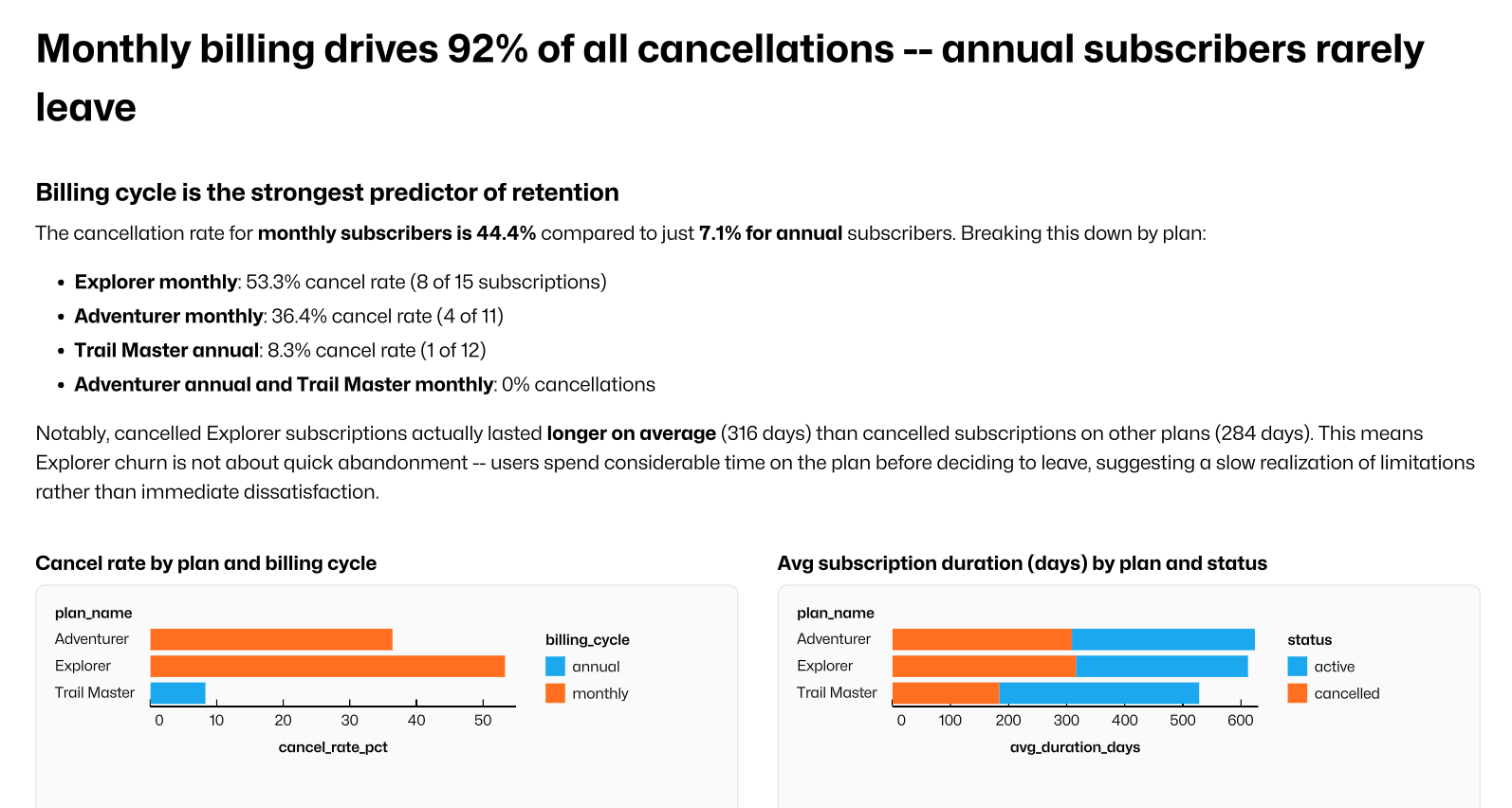
Count’s agent gave me a pretty thorough description of the subscription changes that occurred, even detailing an important insight that the Explorer plan was the most churn-prone plan despite being one of the least used plans. Overall, it’s pretty impressive what it was able to do without data modeling, but imagine what it’s capable of with more direction!
EX: Giving AI agents modeled data
When you give an AI agent modeled data, you’ve already created the structure that it needs. You’ve cleaned the raw data, adjusted for any mistakes, and have applied the proper business logic.
You aren’t depending on AI to solve the hardest part of the data puzzle. Instead, you can hand over the data and give it the business context it needs to then make sense of the data.
Providing this well-documented data model also gives stakeholders direction in their attempts to make sense of the data. They don’t have to guess what is right or wrong, but are instead guided in the right direction.
When given modeled data, not only was Count able to work faster to develop insights and visuals (and aren’t they beautiful?), but it was able to dive deeper into my data with more confidence.
Other BI features for enabling self-service
In addition to an AI agent, stakeholders need space to drill down and explore data that isn’t in a data warehouse and doesn’t involve editing a dashboard. Business stakeholders shouldn’t have data warehouse access. They also shouldn’t be able to edit a dashboard.
With Quicksight, for example, stakeholders have no way to access the data used in dashboards unless they have access to the data warehouse. This created a huge hurdle for stakeholders that required the data team to constantly pull CSVs for them to then ingest into Excel. Or we had to do the “quick” analysis for them. Every. Single. Time.
Talk about a time suck!
Count has a collaborative canvas feature that allows stakeholders to work alongside AI agents, creating their own data resources entirely separate from those the data team has created. This allows stakeholders to build what they need while also leveraging what already exists, and collaborating with others in the meantime.
As much as I want to tell you a tool doesn’t matter, when it comes to self-service BI it does. There are things you will never be able to do unless you have the right tool. I couldn’t collaborate with stakeholders on a data drill down or even give stakeholders access to datasets that allowed them to explore metrics when I used Quicksight.
That being said, a good tool doesn’t allow you to skip the foundations of high quality data.
You still need to build scalable data models, or even the best BI tool will be prone to mistakes. You still need to make sure you are prioritizing the right work and saying no. If you don’t do this, even the best BI tool will be cluttered with useless dashboards and reports.
A solid, AI-enabled BI tool like Count can take you far when you use it the right way. It helps feed a cycle that allows you to put more of your effort towards foundational data models which then improve stakeholders’ self-exploration of metrics.
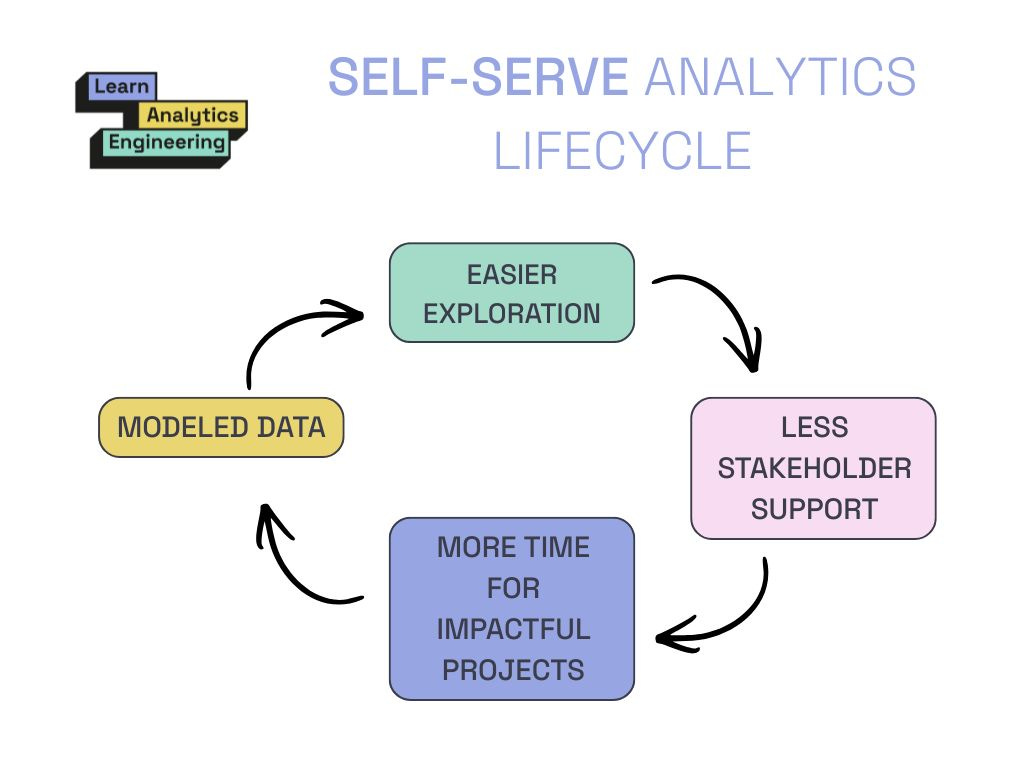
These efforts continue to compound, allowing everyone to focus on the big things that move company KPIs the most.
So no. Self-service analytics is not a myth. 😉 You just need foundational data models and a tool that allows you to make the most out of them.
Have a great week!
Madison
Feels like a promotion for “Count”