

Medallion Architecture 101
Why it's NOT a data modeling strategy but a data design that allows for strong governance and clear expectations for all users
Medallion Architecture is often misunderstood as a data modeling approach. It’s not that.
Whether you are new to analytics engineering or new to modern data stack tools, it’s easy to get caught up in vendor jargon, taking any slice of information they give you as fact.
That’s what happened to me when I first started in analytics engineering and was introduced to dbt. My only experience with “data modeling” was through the dbt docs and their recommended organizational patterns of base, intermediate, and mart models.
At the time, I had no idea that this wasn’t a data modeling approach. Medallion Architecture is to Databricks as base, intermediate, and mart models are to dbt. It’s a powerful approach to organizing data, but it doesn’t replace data modeling. Rather, it’s its own art that deserves its own care and consideration.
After reading her article on Medium about Medallion Architecture, I thought who better to share about what it is and why it’s used than Riki Miko, a Principal Cloud Data Architect at Live Nation Entertainment.
Riki and I worked together at UPS for a few months when I was completing a data architecture internship. That was actually my very first data role ever. I don’t think I even knew how to write SQL at the time, so it’s crazy to come full circle!
What is Medallion Architecture?
At its heart, Medallion Architecture is a layered data design that organizes data into progressively cleaner and more refined layers. Databricks popularized the term, but the concept is rebranding the old practice of refining data progressively through staging tables, enterprise data warehouses, and serving up reliable datasets for analytics.
The layers are usually described as Bronze, Silver, and Gold, and the metaphor is deliberate: raw, refined, and business-ready data. Think of it as leveling up your data from Bronze, Silver, to Gold, where each layer serves a specific purpose.
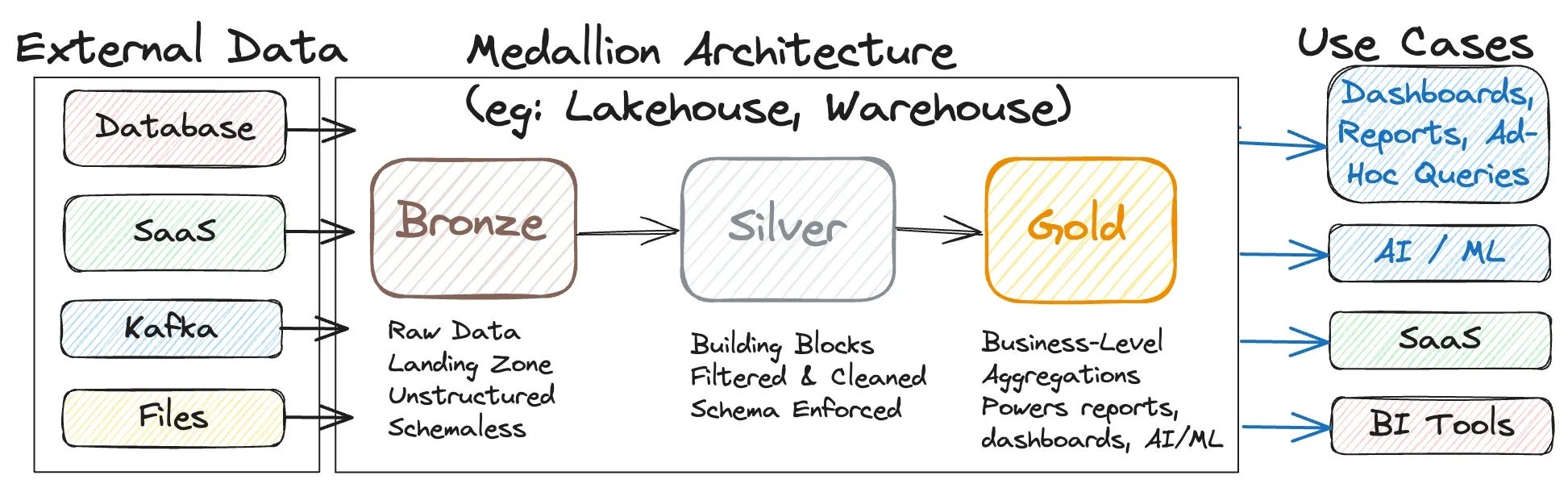
Bronze
This is the raw ingestion layer. It’s where semi-structured or unstructured source data arrives with minimal processing. History may be captured here, but that can vary. Bronze is the chaotic landing pad for all sources.
If we are comparing this to dbt standards, this would be your raw data sources.
Silver
This layer contains standardized, cleaned, and aligned data. It is typically normalized with deduplication, conforming keys, and unified terminology. Silver integrated multiple sources to create a single, reliable source of truth for a specific domain that all downstream teams can trust.
While this doesn’t directly compare to dbt’s standards, you can think of this as a mix between staging models and intermediate models.
Gold
This layer includes business-ready, consumption-focused data products where your data is truly usable. These can be star schemas, wide tables, curated views, or any model designed to address a business need. Gold isn’t necessarily “perfect” by database theory standards, but it is usable, reliable, and refreshed at a regular candance. It’s the layer your analysts and business users actually touch to make decisions.
In dbt, this is similar to your mart models.
These different layers act as an operating model that ensures repeatable, governed patterns with clear lineage, giving both engineers and analysts confidence in the data they want to use.
Why use Medallion Architecture?
Medallion architecture provides clarity and guardrails for everyone in the data ecosystem by tackling real issues in data management and analytics. Engineers know where data should land, analysts understand which layers are trustworthy, and leadership can trust that reports will be consistent.
Data producers can land data in Bronze, and central teams can refine Silver and Gold iteratively as business use cases arise. Depending on your organization’s structure, data producers, central teams, and consumers may play different roles at each step in creating and managing a data product’s lifecycle, but they are all working together within Medallion frameworks to create curated data.
Cost and performance are major drivers for medallion architecture. Without a standardized Silver layer, Gold can become a messy collection of one-off ETL jobs, driving ballooning compute costs, duplicated work, and inconsistent outputs (sound familiar?).
This was especially common during cloud migrations when formalized data modeling took a back seat, and now teams are rediscovering the value of structured pipelines.
Processing and integrating data upstream in Silver leads to fewer re-computes, more reuse, and more consistent reports for consumers. It reduces redundant work, makes pipelines predictable, and provides a reliable foundation for multiple Gold-level datasets (similar to the purpose of dbt’s intermediate models!).
There are also use-case distinctions. Gold is often the access point for analytics and dashboards, while sometimes Silver can serve as the sweet spot for ML feature stores, providing clean and conformed data that isn’t over-aggregated. Medallion architecture is a multi-purpose backbone supporting analytics, machine learning, and AI workloads.
What this looks like in practice
Understanding the distinction between Silver and Gold is crucial.
Silver is your clean, integration foundation. It’s where messy multi-source data is harmonized into domain-level models, typically in a normalized, third normal form(ish) format that is still optimal for storage and access while keeping data integrity in mind.
Gold is curated, business-ready data that supports reporting, analytics, and decision-making.
Imagine that you’re a Cloud Data Architect at a live event company, and you need to integrate orders across multiple ticketing platforms.
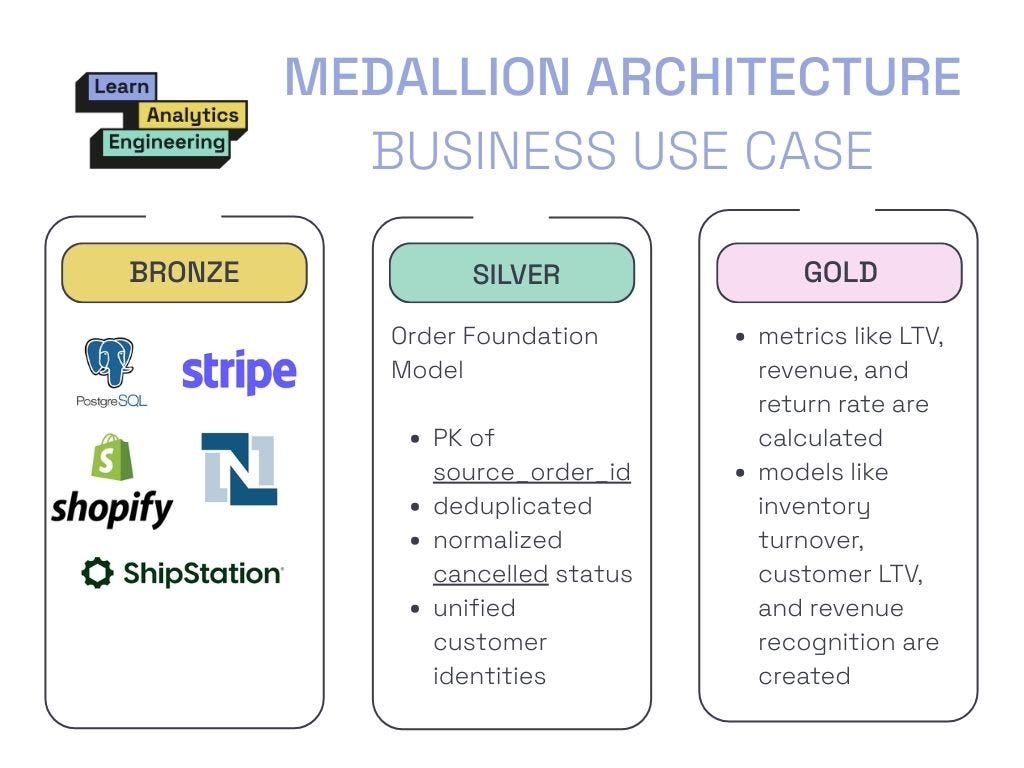
Bronze lands the chaos. Here you have five platforms, all with different field names and inconsistent structures.
Silver transforms that chaos into a unified “Order Foundation Model”. Fields are standardized across all system of record sources (order_id, purchase_number, trans_id all turn into one source_order_id), statuses are normalized (CANCELLED, VOID, X all turn into one cancelled status), duplicates are deduplicated, and customer identities are reconciled.
The end result is one source of truth per organizational domain that all downstream Gold models can rely on.
Gold, in turn, aggregates and applies business logic, producing star schemas, wide tables, or curated views.
Bronze isn’t “bad” and Gold isn’t “star schemas only”. Bronze is messy but valuable, Silver ensures a clean foundation, and Gold is about usability and trust. Depending on how your organization is set up, its size, and its reporting needs, this can be debated and adopted from a purist mindset to fit your needs.
It’s also worth noting how tools like dbt fit into this picture. dbt’s staging, intermediate, and mart layers can help implement transformations inside Silver and Gold, but medallion architecture itself is the backbone, dictating how data flows, matures, and where it lands. Bronze is raw, Silver integrates and deduplicates, and Gold is curated for consumption.
dbt is the engine that powers these transformations that helps to implement the logic for each layer, but it doesn’t define the overall architecture. Think of medallion as the road network your data drives on, and dbt as the engine under the hood.
Next week we’ll dive deeper into Medallion Architecture vs dimensional modeling and the most common mistakes and anti-patterns when using it in practice.
If you have any specific questions feel free to drop them in the comments for us to touch on.
Don’t forget to follow Riki on Medium for more insights on Databricks, Medallion Architecture, and data strategy!
Have a great week!
Madison
Excellent clarification on the distinction between data organization and data modeling. The metaphor of dbt being the engine and medallion architecture being the road network really clicks. I've seen too many teams confuse Silver layer normalization with actual dimensional modeling and then wonder why their Gold layer ends up as a collection of one-off ETL jobs. The point about standardizng upstream in Silver to reduce redundant compute is huge, especially when cloud costs start piling up fast.